引言
脑电波是一类由大脑中局部群体神经元同步放电所形成的具有时空特征的脑电活动电波。德国医生汉斯·伯格(Hans Berger)在1924年首次在人的头骨上记录到脑电波图(electroencephalography,EEG)。心理学研究表明,人类的认知和感知可以通过脑电波来表达。当大脑的嗅觉、听觉、视觉、味觉及触觉神经受到刺激时,其刺激反应信号可以通过脑电波表达出来,从而揭示感官和人员之间的心理关联性。其中大量研究展示了使用脑电信号连续确定个人舒适感的可行性,并且可以得到更加客观的数据。近来则有研究表明触觉刺激与脑电波的θ,α,β这三个频段均存在关联性。
传统的情绪识别主要是基于面部特征、肢体动作和语音的研究,这些外在特征容易伪装,并不能反应出真实的情绪,脑电信号可以反映大脑在加工情绪时所伴随的神经电生理活动,能够很好的弥补传统研究方法的缺陷。
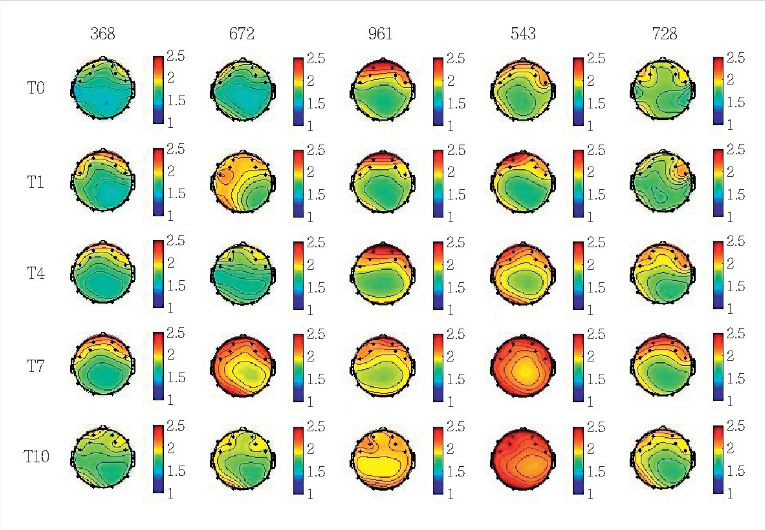
故本项目通过使用python语言搭建KNN机器学习算法实现对EEG脑电波数据的情绪分析分类。其最终实现的效果如下图可见:
是一种理论上比较成熟的智能算法,最初由Cover和Hart于1968年提出。kNN算法思路简单直观:对于给定的测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测。
kNN方法可以实现分类任务和回归任务。在分类任务中,一般使用“投票法”,即在k个“近邻”样本中出现最多的种类标记作为预测结果。在回归任务中,一般使用“平均法”,即将这k个样本的实值输出标记的平均值作为预测结果。在定义了相似度评价准则后,还可以基于相似度的大小进行加权投票和加权平均。相似度越大的样本权重越大。其中KNN算法分类流程如下图:
No.2 “模型搭建”
数据集准备
首先我们使用官方提供的EEG数据集,放置data文件夹下:
数据特征提取
首先我们使用官方提供的EEG数据集,放置data文件夹下:
通过使用pickle实现对dat数据文件的读取,获取各个数据文件中特征向量,并在每个信道中进行fft。
其中输入:维数为N × M的通道数据,N为通道个数,M为每个通道的脑电图数据个数。
输出:维度为N x M的FFT结果。N表示信道数,M表示每个信道的FFT数据数。
关键代码如下:
for file in os.listdir("../data"):
fname = Path("../data/"+file)
x = cPickle.load(open(fname, 'rb'), encoding="bytes")
for i in range(40):
num+=1
eeg_realtime = x[b'data'][i]
label = x[b'labels'][i]
if label[0] >6:
val_v = 3
elif label[0] < 4:
val_v = 1
else:
val_v = 2
if label[1] > 6:
val_a = 3
elif label[1] < 4:
val_a = 1
else:
val_a = 2
if i < 39:
va_label.write(str(val_v) + ",")
ar_label.write(str(val_a) + ",")
if num==1280:
va_label.write(str(val_v) )
ar_label.write(str(val_v) )
eeg_raw = np.reshape(eeg_realtime, (40, 8064))
eeg_raw = eeg_raw[:32, :]
eeg_feature_arr = self.get_feature(eeg_raw)
for f in range(160):
if f == 159:
fout_data.write(str(eeg_feature_arr[f]))
else:
fout_data.write(str(eeg_feature_arr[f]) + ",")
fout_data.write("\n")
print(file + " Video watched")
然后从计算fft得到所有通道的频率。输入:维数为N × M的通道数据,N为通道个数,M为每个通道的脑电图数据个数。输出:每个通道的频带:Delta, Theta, Alpha, Beta和Gamma。
# Length data channel
L = len(all_channel_data[0])
# Sampling frequency
Fs = 128
# Get fft data
data_fft = self.do_fft(all_channel_data)
# Compute frequencymotio
frequency = map(lambda x: abs(x // L), data_fft)
frequency = map(lambda x: x[: L // 2 + 1] * 2, frequency)
f1, f2, f3, f4, f5 = itertools.tee(frequency, 5)
# List frequency
delta = np.array(list(map(lambda x: x[L * 1 // Fs - 1: L * 4 // Fs], f1)))
theta = np.array(list(map(lambda x: x[L * 4 // Fs - 1: L * 8 // Fs], f2)))
alpha = np.array(list(map(lambda x: x[L * 5 // Fs - 1: L * 13 // Fs], f3)))
beta = np.array(list(map(lambda x: x[L * 13 // Fs - 1: L * 30 // Fs], f4)))
gamma = np.array(list(map(lambda x: x[L * 30 // Fs - 1:L * 50 // Fs], f5)))
模型预测
从特征得到arousal值和valence值。其中Valence-Arousal分别代表情绪的正负向程度和激动程度,基于这两个维度可以构成一个情感平面空间,任何一个情感状态可以通过具体的Valence-Arousal数值,映射到VA平面空间中具体的一个点。
输入:来自所有频带和信道的特征(标准差和平均值),维度为1 × M(特征数量)。
输出:由每一种arousal和valence产生的1至3级情绪。1表示低,2表示中性,3表示高。
self.train_arousal = self.train_arousal[40*(index-1):40*index]
self.train_valence = self.train_valence[40*(index-1):40*index]
self.class_arousal = np.array([self.class_arousal[0][40*(index-1):40*index]])
self.class_valence = np.array([self.class_valence [0][40*(index-1):40*index]])
distance_ar = list(map(lambda x: ss.distance.canberra(x, feature), self.train_arousal))
# Compute canberra with valence training data
distance_va = list(map(lambda x: ss.distance.canberra(x, feature), self.train_valence))
# Compute 3 nearest index and distance value from arousal
idx_nearest_ar = np.array(np.argsort(distance_ar)[:3])
val_nearest_ar = np.array(np.sort(distance_ar)[:3])
# Compute 3 nearest index and distance value from arousal
idx_nearest_va = np.array(np.argsort(distance_va)[:3])
val_nearest_va = np.array(np.sort(distance_va)[:3])
# Compute comparation from first nearest and second nearest distance.、If comparation less or equal than 0.7, then take class from the first nearest distance. Else take frequently class.
# Arousal
comp_ar = val_nearest_ar[0] / val_nearest_ar[1]
然后从特征中获取情感类。
输入:来自所有频段和信道的特征(标准偏差),尺寸为1 × M(特征数量)。
输出:根据plex模型,情绪在1到5之间的类别。
class_ar, class_va = self.predict_emotion(feature,fname)
print(class_ar, class_va)
if class_ar == 2.0 or class_va == 2.0:
emotion_class = 5
if class_ar == 3.0 and class_va == 1.0:
emotion_class = 1
elif class_ar == 3.0 and class_va == 3.0:
emotion_class = 2
elif class_ar == 1.0 and class_va == 3.0:
emotion_class = 3
elif class_ar == 1.0 and class_va == 1.0:
emotion_class = 4
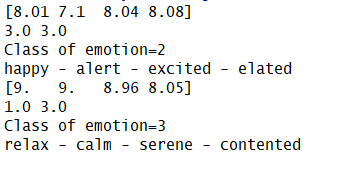
预测结果如下图可见:
完整代码
链接:
https://pan.baidu.com/s/1BX58sJv037eIJx9A8jWt3g
提取码:rwpe