
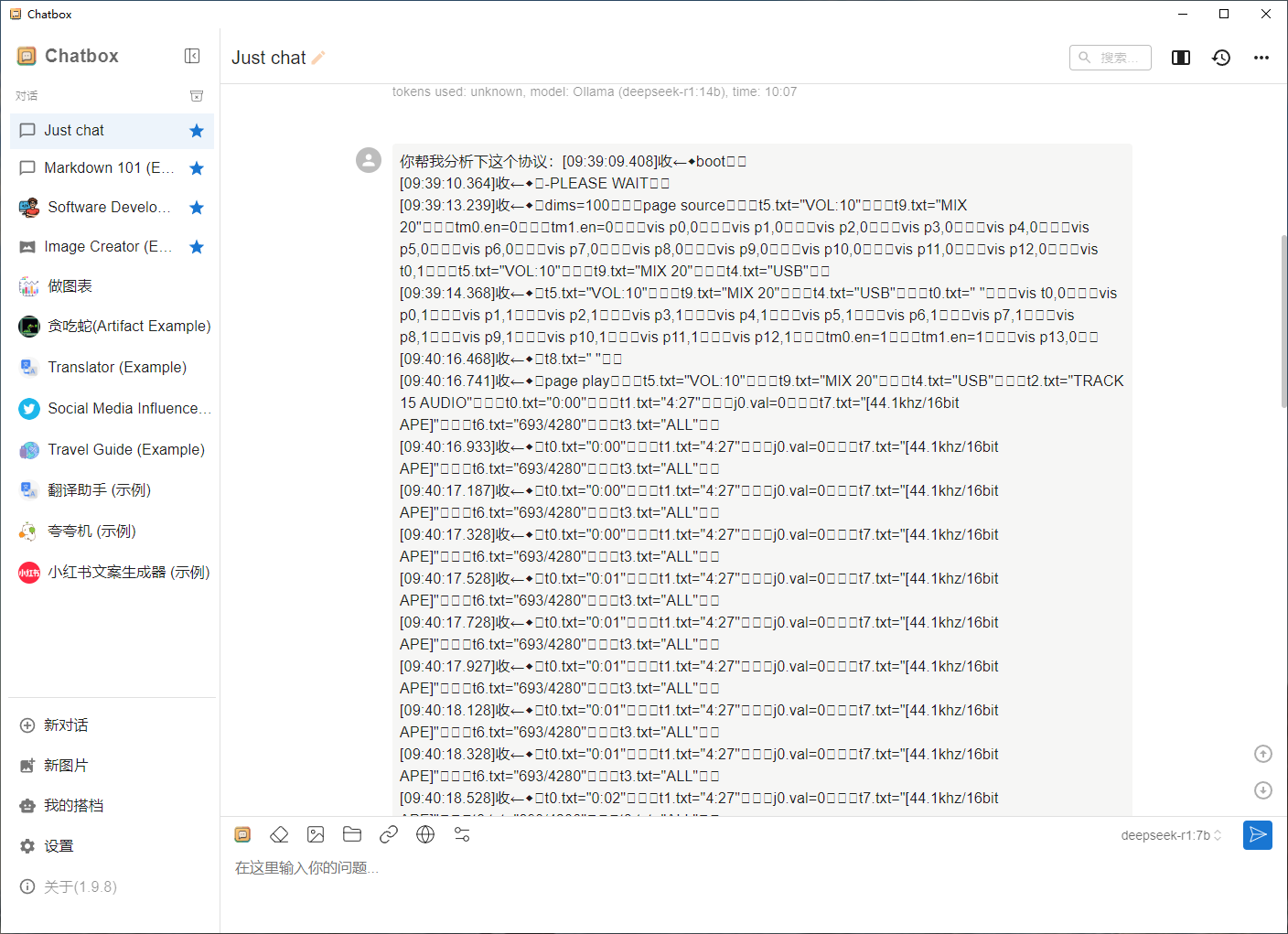
用离线的DeepSeek大模型编写程序
离线模型测试
测试用的机器A
- E5-2697 V2 单路
- AMD FirePro D700 双显卡
- 内存 64G
- 测试操作系统:Window10 专业版 64位
测试用的机器B
- E5-4669 V4 双路
- RTX 3060 单显卡
- 内存128G
- 测试操作系统:Window10 企业版 64位
测试结果
先说测试结果,模型大小越大要求的性能越高,还有要开启GPU支持的,必须要用NVDIA的卡,带CUDA功能,AMD的卡不支持。
用deepseek辅助编程,只用几个步骤, 1. 下载ollama 2. 安装deepseek模型 3. 安装VSCODE的CodeGPT插件 4. 使用插件进行编码,重构等操作
什么是ollama?
ollama是一个简明易用的本地大模型运行框架,只需一条命令即可在本地跑大模型。
开源项目,专注于开发和部署先进的大型语言模型(LLM)。
官网地址:https://ollama.com/
Github: https://github.com/ollama/ollama
开源的本地大模型运行框架 Ollama是一个开源的本地大模型运行框架,旨在简化大型语言模型(LLM)的部署和运行过程。
它通过提供简单的安装和配置指令,使得用户能够快速在本地运行开源大型语言模型,如Llama 3.1、Mistral、Gemma 2等。
主要特点和功能
开源:Ollama是一个完全开放源代码的项目,任何人都可以查看、修改和贡献代码。 易用性:项目旨在简化语言模型的训练和部署流程,即使是那些没有深度学习背景的人也能轻松使用。 高性能:Ollama支持高效地训练和运行大规模的语言模型,利用现代硬件加速计算。 模型管理:用户可以方便地下载和管理各种语言模型,并根据需求选择适合的模型进行使用。 本地运行优势:在本地运行模型可以保护数据隐私,避免数据传输到外部服务器带来的潜在风险,并且不受网络波动的影响。 跨平台支持:提供针对macOS、Windows、Linux以及Docker的安装指南,确保用户能在多种操作系统环境下顺利部署和使用Ollama。
应用场景
开发和测试:开发人员可以使用Ollama在本地快速搭建语言模型环境,用于开发新的语言相关的应用程序,进行初步测试和优化。 个人学习和研究:对于研究自然语言处理的学者或对语言模型感兴趣的个人来说,Ollama提供了一个方便的实验平台,可以在本地加载不同的模型,对比它们的性能,研究模型的输出特性。 企业应用:企业内部有一些敏感的文档需要通过语言模型进行处理和分析时,使用Ollama在本地运行模型,可以避免数据传输到外部服务器带来的潜在风险。
安装离线版的DeepSeek模型
deepseek模型版本选择
查看不同的版本,选择合适的版本下载
https://ollama.com/library/deepseek-r1:7b
下面是选择了7b的这个模型,大小是4.7G
打开控制台输入:
ollama run deepseek-r1:7b
运行效果
目前是运行在CPU的模式下,没有优先用GPU运行
7B效果
ollama run deepseek-r1:7b
7b的运行效果,有点啰嗦
14b效果
这是14b效果,比7b的要智能点
ollama run deepseek-r1:14b
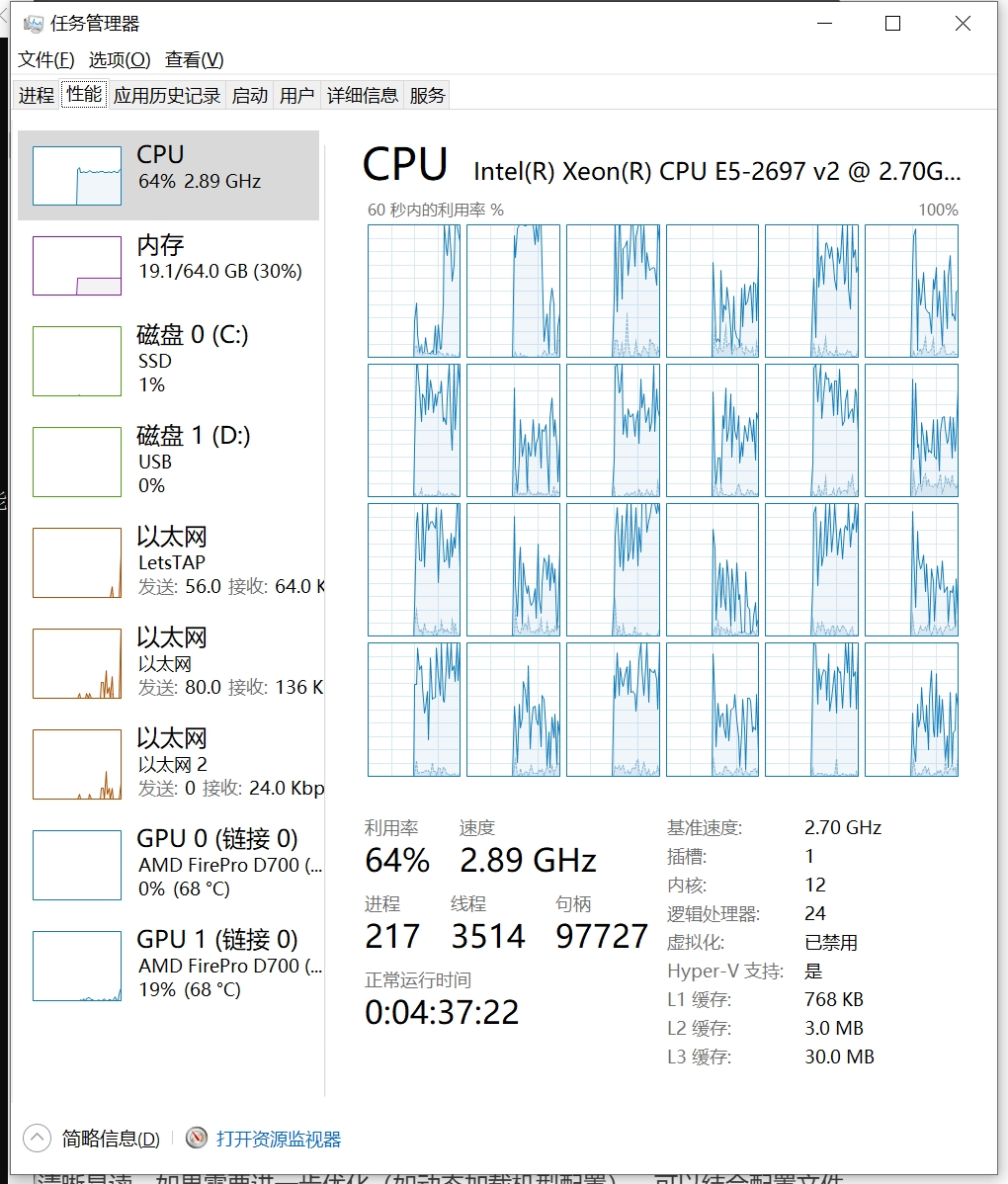
CPU和GPU使用情况
在CPU的情况下,性能还是有点差,必须优先用显卡运行
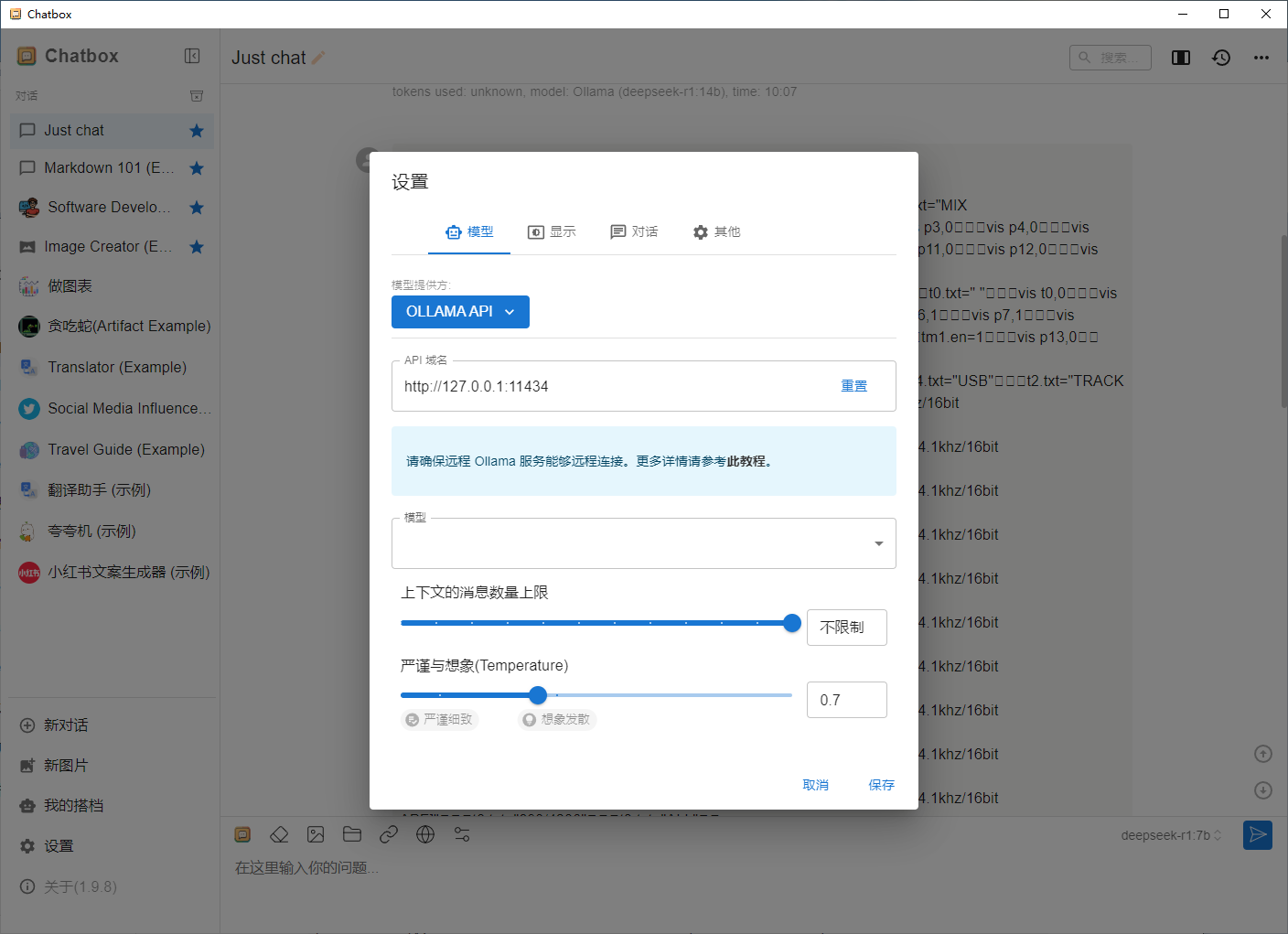
配合Chatbox实现本地化聊天
网站 https://chatboxai.app/zh#download
开启远程使用
在 Windows 上配置
在 Windows 上,Ollama 会继承你的用户和系统环境变量。
通过任务栏退出 Ollama。
打开设置(Windows 11)或控制面板(Windows 10),并搜索“环境变量”。
 点击编辑你账户的环境变量。
点击编辑你账户的环境变量。
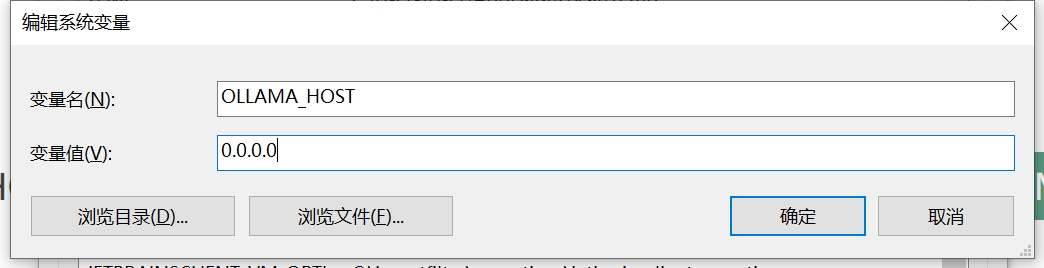
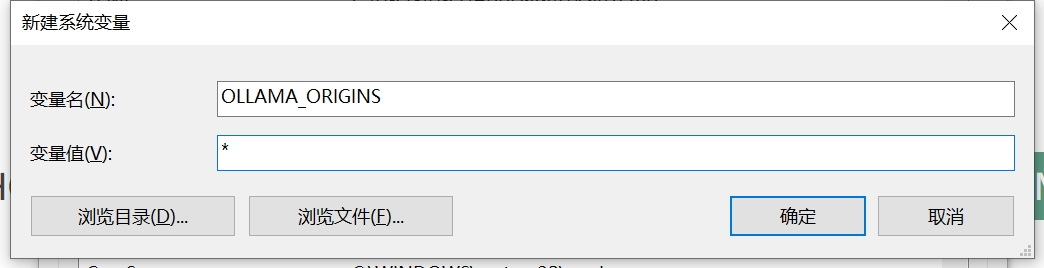
为你的用户账户编辑或创建新的变量 OLLAMA_HOST,值为 0.0.0.0; 为你的用户账户编辑或创建新的变量 OLLAMA_ORIGINS,值为 *。
 点击确定/应用以保存设置。
点击确定/应用以保存设置。
从 Windows 开始菜单启动 Ollama 应用程序。
在 Linux 上配置
如果 Ollama 作为 systemd 服务运行,应使用 systemctl 设置环境变量:
调用 systemctl edit ollama.service 编辑 systemd 服务配置。这将打开一个编辑器。
在 [Service] 部分下为每个环境变量添加一行 Environment:
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
保存并退出。
重新加载 systemd 并重启 Ollama:
systemctl daemon-reload
systemctl restart ollama
服务 IP 地址 配置后,Ollama 服务将能在当前网络(如家庭 Wifi)中提供服务。你可以使用其他设备上的 Chatbox 客户端连接到此服务。
Ollama 服务的 IP 地址是你电脑在当前网络中的地址,通常形式如下:
192.168.XX.XX
在 Chatbox 中,将 API Host 设置为:
注意事项
可能需要在防火墙中允许 Ollama 服务的端口(默认为 11434),具体取决于你的操作系统和网络环境。 为避免安全风险,请不要将 Ollama 服务暴露在公共网络中。家庭 Wifi 网络是一个相对安全的环境。
开启GPU支持
在使用Ollama时,若想优先使用GPU进行计算,可以按照以下步骤进行配置:
确认GPU驱动和CUDA已安装 确保系统已安装GPU驱动和CUDA工具包,并验证CUDA是否正常工作。
安装支持GPU的Ollama版本 Ollama可能提供支持GPU的版本,需确保安装的是该版本。
配置Ollama使用GPU 通过环境变量或配置文件指定Ollama使用GPU。
方法一:通过环境变量
在运行Ollama前,设置环境变量以启用GPU支持。
Windows下修改:
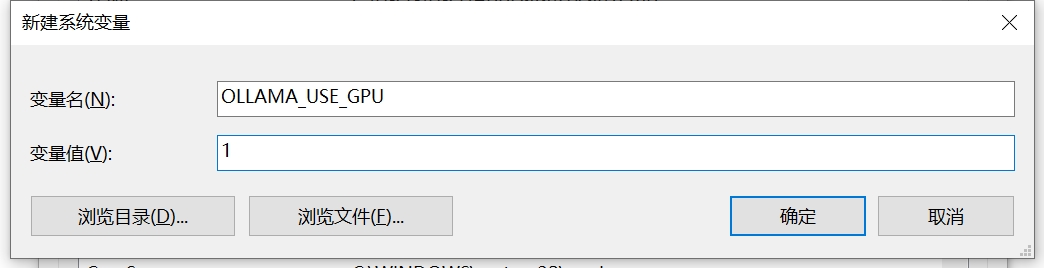 Linux下修改
例如:
Linux下修改
例如:
export OLLAMA_USE_GPU=1
重新运行模型
ollama run 你自己的模型名字
方法二:通过配置文件 如果Ollama支持配置文件,可以在其中指定使用GPU。 例如:
use_gpu: true
验证GPU使用 运行Ollama后,检查日志或使用nvidia-smi命令确认GPU是否被调用。
调整GPU资源 根据需要,调整Ollama使用的GPU资源,如显存分配或指定特定GPU。
示例 假设Ollama支持GPU并通过环境变量启用:
export OLLAMA_USE_GPU=1
重新运行模型
ollama run 你自己的模型名字
运行后,使用nvidia-smi查看GPU使用情况。
注意事项
确保GPU资源充足。 不同版本的Ollama配置方式可能不同,请参考官方文档。
配置环境变量
这里综合了所有环境变量:
OLLAMA_HOST=0.0.0.0 解决外网访问问题
OLLAMA_MODELS=E:\ollamaimagers 解决模型默认下载C 盘的问题
OLLAMA_KEEP_ALIVE=24h 设置模型加载到内存中保持24个小时(默认情况下,模型在卸载之前会在内存中保留 5 分钟)
OLLAMA_HOST=0.0.0.0:8080 解决修改默认端口11434端口
OLLAMA_NUM_PARALLEL=2 设置2个用户并发请求
OLLAMA_MAX_LOADED_MODELS=2 设置同时加载多个模型
以上就是我们常用到的属性,通过以上设置能够更加方便使用ollama.
模型管理
运行了一堆的模型后,留下了一些不合适的,这时候怎么管理呢? 用ollama 指令来操作:
查看当前运行的模型
D:\>ollama ps
NAME ID SIZE PROCESSOR UNTIL
列出可用的模型
D:\>ollama list
NAME ID SIZE MODIFIED
deepseek-r1:32b 38056bbcbb2d 19 GB 4 days ago
deepseek-r1:14b ea35dfe18182 9.0 GB 4 days ago
deepseek-r1:7b 0a8c26691023 4.7 GB 4 days ago
删除模型
D:\dzkj_works\G80_pannel\Firmware\g80-panel-firmware>ollama rm deepseek-r1:32b
deleted 'deepseek-r1:32b'
Ollama 相关命令
下面介绍的是ollama详细指令: Ollama 提供了多种命令行工具(CLI)供用户与本地运行的模型进行交互。
我们可以用 ollama –help 查看包含有哪些命令:
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
1、使用方法
ollama [flags]:使用标志(flags)运行 ollama。
ollama [command]:运行 ollama 的某个具体命令。
2、可用命令
- serve:启动 ollama 服务。
- create:根据一个 Modelfile 创建一个模型。
- show:显示某个模型的详细信息。
- run:运行一个模型。
- stop:停止一个正在运行的模型。
- pull:从一个模型仓库(registry)拉取一个模型。
- push:将一个模型推送到一个模型仓库。
- list:列出所有模型。
- ps:列出所有正在运行的模型。
- cp:复制一个模型。
- rm:删除一个模型。
- help:获取关于任何命令的帮助信息。
3、标志(Flags)
-h, –help:显示 ollama 的帮助信息。 -v, –version:显示版本信息。
在VSCode上对接DeepSeek
在插件市场上搜索 CodeGPT 下载安装,并配置好

